In keeping with our philosophy to provide access to information for people who are blind or visually impaired, the American Printing House for the Blind provides accessible print materials for braille readers. Download HTML and BRF versions of this Guidebook at www.aph.org/manuals/
This publication is protected by Copyright and permission should be obtained from the publisher prior to any reproduction, storage in a retrieval system, or transmission in any form or by any means electronic, mechanical, photocopying, recording, or otherwise. For information regarding permission, contact the publisher at the following address:
American Printing House for the Blind 1839 Frankfort Avenue Louisville, KY 40206 800-223-1839 www.aph.org or [email protected]
Reference Citation: Hoffmann, R. (2017). Protein synthesis kit guidebook. Louisville, KY: American Printing House for the Blind.
The Project Leader thanks the following field testers and their students for their valuable time and input during the development of the Protein Synthesis Kit: Carlton Cook-Walker, Sylvia Ekdahl, Kate Fraser, Jan Megarry, Jane Mundschenk, Alan Roth, Elizabeth Eagan Satter, Ava Silverstein, and Louise Whitworth.
Introduction
The Protein Synthesis Kit (PSK) builds upon the concepts introduced by the DNA-RNA Kit. Together they demonstrate in large part the function of genetic material in all cells. The DNA-RNA Kit demonstrates transcription, or how deoxyribonucleic acid (DNA) is used as a template to form the molecular intermediate, messenger ribonucleic acid (mRNA). The PSK demonstrates translation, or how mRNA is used to form chains of linked amino acids which make up all different kinds of proteins involved in cellular activities. Some examples of proteins include enzymes needed for chemical reactions like transcription and translation; structural proteins like keratin and collagen found in hair, nails, and skin; hemoglobin in red blood cells needed for oxygen delivery to body cells; and antibodies that provide protection against disease.
Both DNA and RNA are formed by linked nucleotide subunits, but there are differences between the two. All nucleotides are composed of a phosphate, a sugar, and a base. A DNA nucleotide contains the sugar deoxyribose, a phosphate, and either the base Adenine (A), Guanine (G), Cytosine (C), or Thymine (T). An RNA nucleotide contains the sugar ribose, a phosphate, and either the base Adenine (A), Guanine (G), Cytosine (C), or Uracil (U). Nucleotides are typically identified by the capital letter of the base they contain.
Chromosomes are double strands of DNA found in the nucleus or center of all cells. Genes are sections of chromosomes which code for the proteins in a cell. Because all proteins are not needed by a cell all at the same time, RNA acts as a messenger to tell the cell that a particular protein is needed at a particular time. A section of DNA (a gene) is transcribed to RNA, and RNA is translated to a protein, as shown in the following sequence:
DNA ➝ RNA ➝ Protein
A protein-coding gene is a single strand of DNA that is used as a template to form a complementary strand of mRNA. This process, known as transcription, uses base-pairing rules to form the mRNA strand:
A pairs with U, T pairs with A, G pairs with C, and C pairs with G.
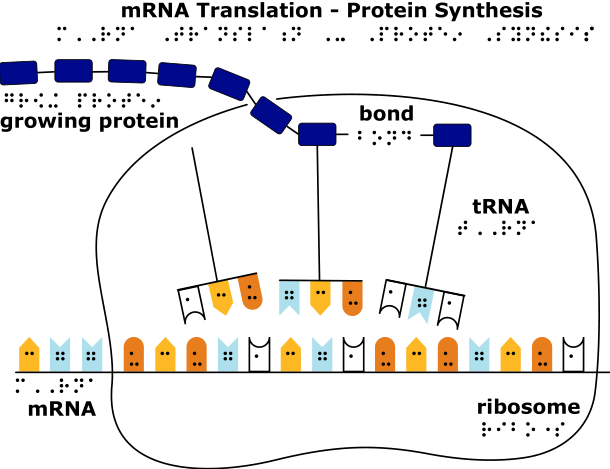
A transcribed length of mRNA peels off the DNA template. Translation takes place when the sequence of nucleotides in mRNA is decoded to a sequence of connected amino acids, which is the primary structure of all proteins. In addition to mRNA, translation requires a molecule that interprets the sequence of mRNA nucleotides and brings the correct amino acid to the growing chain; this molecule is called transfer RNA, or tRNA. The ribosome, a special complex of RNA and protein, and several enzymes physically coordinate translation by binding to the mRNA and providing a place for tRNA molecules to deliver their amino acids. The PSK demonstrates the formation of tRNA and its function during translation, but it does not include the ribosome or associated enzymes. The reader is referred to the suggested websites of this Guidebook for more information about this process.
Genetic information in DNA and mRNA is coded in the order of linked nucleotides that make up each strand. Every triplet of three nucleotides along the length of an mRNA strand codes for one of 20 amino acids or a stop signal. For this reason, triplets are also known as codons. The order of the codons ultimately determines the order of linked amino acids during the translation process. The meaning of each codon is interpreted by the cell according to the genetic code. The genetic code consists of the 64 different three-letter combinations of the four nucleotides (A, C, G, and U) and the amino acids or stop signal for which they code.
Amino acids are carried to the mRNA-ribosome complex by tRNA molecules. Part of each tRNA molecule consists of a triplet of nucleotides called an anticodon that base-pairs with complementary mRNA codons according to the following rules:
A pairs with U, U pairs with A, G pairs with C, and C pairs with G.
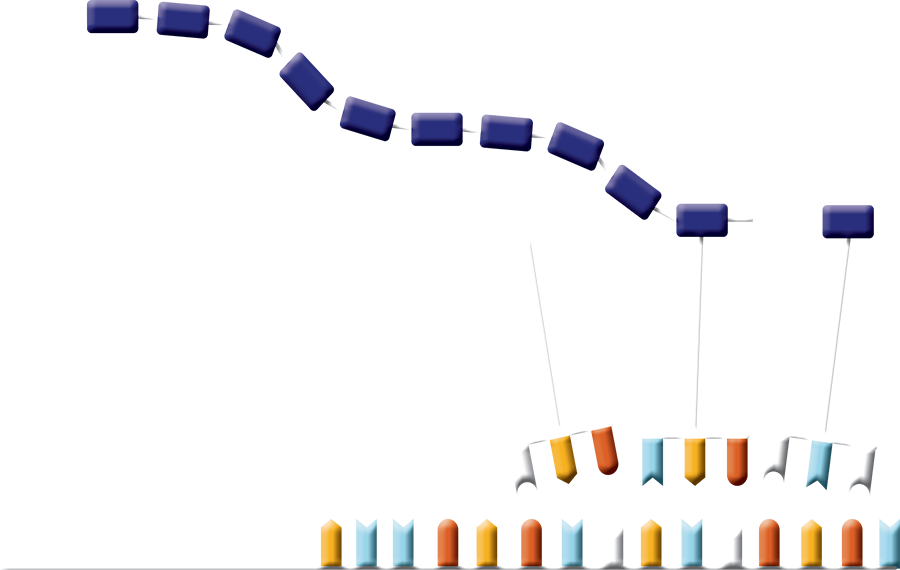
Codon-anticodon base-pairing ensures that the correct amino acids are delivered in a specified order. For example, the anticodons found on the tRNAs for the amino acids Tryptophan and Lysine are ACC and UUU, respectively, which base-pair with the mRNA codons UGG and AAA. Translation of a strand of mRNA including the ribosome, mRNA, tRNA and anticodon-codon base-pairing is shown on the separate tactile graphic included in the PSK.
As in the DNA-RNA Kit, the PSK contains jigsaw puzzle-like pieces, but in this case they represent some of the molecular players in the process of translation. After a strand of mRNA is constructed, students determine which amino acids are specified using the genetic code—this is also known as decoding mRNA. Students then construct tRNA molecules consisting of an amino acid and its three-nucleotide anticodon using base-pairing rules. Recall that the anticodon is the part of the tRNA molecule that base-pairs with the mRNA codon for a particular amino acid. In this way, tRNA molecules bring amino acids to the mRNA-ribosome complex and ensure their correct order to form the protein. A linked amino acid sequence is revealed after the mRNA strand and tRNA anticodons are removed.
Information about Kit Components
Genetic Code in Large Print and Braille
The Genetic Code is used to decode mRNA and identify specified amino acids. A pack of 10 sets of the large print braille genetic code is included in the kit.
RNA Nucleotides
The PSK includes 16 each of the four types of transfer RNA (tRNA) nucleotides (A, C, G, and U). Transfer RNA nucleotides are smaller, modified versions of the mRNA nucleotides included in the DNA-RNA Kit. RNA subunits from both kits share the following features:
white foam backing
colored surface laminate (white, light blue, yellow, or orange)
raised circle tactile symbol (to represent the sugar ribose)
capital print letter A (white), C (yellow), G (light blue), or U (orange)
braille lower case letter A, C, G, or U
Corresponding versions of mRNA nucleotides (from the DNA-RNA Kit) and tRNA nucleotides (from the PSK) are shown below on the left and right, respectively. Both types of RNA nucleotide subunits have directionality: the sugar side is represented by the raised circle, and the phosphate side is represented by raised diagonal lines in mRNA subunits or flat laminate in tRNA subunits.
White subunits – Adenosine monophosphate (A)
Light blue subunits – Guanosine monophosphate (G)
Yellow subunits – Cytidine monophosphate (C)
Orange subunits – Uridine monophosphate (U)
Amino Acids
Each one of the 20 different amino acids is represented by a rectangular subunit made of dark blue foam and smooth, dark blue laminate. In the PSK, there are two complete sets of 20, labeled in print and braille.
Start and Stop Subunits
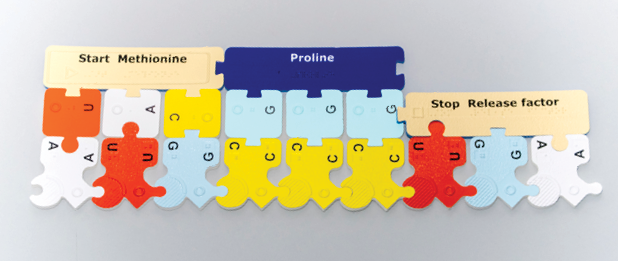
The rectangular subunits made of dark blue foam and tan laminate represent Start Methionine and Stop Release factor. The PSK includes four Start subunits, tactually identifiable by a raised line around the edge of each piece and a right-pointing triangle symbol before the brailled word “Start.” Start subunits are also labeled “Methionine” because most often this is the first amino acid in the chain of amino acids that make up a protein.
The PSK includes two each of three different Stop subunits, tactually identifiable by a sandy-textured surface laminate and a square symbol before the brailled word “Stop.” These subunits are also labeled “Release factor” because the mRNA codons that signify Stop are not recognized by tRNA molecules. Rather, Stop codons bind with a special protein called the Release factor which stops the translation process. Because there are three different Stop codons (UGA, UAA, and UAG), the PSK includes three corresponding Stop Release factor subunits. UGA corresponds to Release factor 1, UAA corresponds to Release factor 2, and UAG corresponds to Release factor 3.
Transfer RNA (tRNA)
Three linked tRNA subunits represent the anticodon part of a tRNA molecule, which also holds an amino acid. The PSK tRNA subunits have a trapezoid blank on one side that links to the trapezoid tabs on the Start Methionine and amino acid subunits.
Anticodons link directly to the amino acid as in Start Methionine above, and Proline below.
Base-pairing Rules
On the opposite side of each tRNA nucleotide subunit there is a blank or tab that allows complementary base-pairing with mRNA nucleotides. This allows anticodon–codon linkage, which follows the RNA base-pairing rules, stated below.
Cytosine always pairs with Guanine: Yellow (C) subunit trapezoid blank links with light blue (G) subunit trapezoid tab.
Guanine always pairs with Cytosine: Light blue (G) subunit trapezoid tab links with yellow (C) subunit trapezoid blank.
Adenine always pairs with Uracil: White (A) subunit large round blank links with orange (U) subunit large round tab.
Uracil always pairs with Adenine: Orange (U) subunit large round tab links with white (A) subunit large round blank.
Translation Graphic
A full color tactile rendering of the process of mRNA translation is included in the kit. The same graphic is reproduced below.
Instructions
Linking and Unlinking Subunits
To link subunits together, press the tab or blank of one piece down into the appropriate tab or blank of another piece.
tRNA nucleotide to amino acid:
mRNA nucleotide to tRNA nucleotide:
Amino acid to amino acid:
To separate attached subunits pull them apart horizontally in the plane of their attachment.
Do not twist the subunits apart!
Do not separate the subunits vertically!
These actions will cause the laminate to separate from the foam.
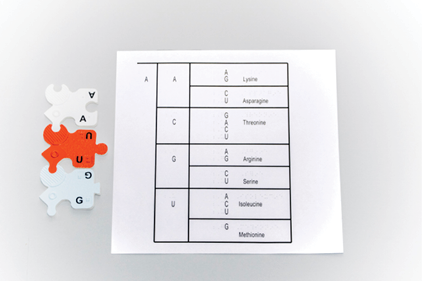
How to Use the Genetic Code
Universal Genetic Code Messenger RNA (mRNA) Codons and Amino Acids
Amino Acid
Codons
Alanine
GCU
GCC
GCA
GCG
Arginine
AGA
AGG
CGU
CGC
CGA
CGG
Asparagine
AAU
AAC
Aspartic acid
GAU
GAC
Cysteine
UGU
UGC
Glutamic acid
GAA
GAG
Glutamine
CAA
CAG
Glycine
GGU
GGC
GGA
GGG
Histidine
CAU
CAC
Isoleucine
AUU
AUC
AUA
Leucine
UUA
UUG
CUU
CUC
CUA
CUG
Lysine
AAA
AAG
Methionine (START)
AUG
Phenylalanine
UUU
UUC
Proline
CCU
CCC
CCA
CCG
Serine
AGU
AGC
UCU
UCC
UCA
UCG
Threonine
ACU
ACC
ACA
ACG
Tryptophan
UGG
Tyrosine
UAU
UAC
Valine
GUU
GUC
GUA
GUG
STOP
UGA
UAA
UAG
The genetic code is used to interpret the nucleotide triplets that make up mRNA. To use the alphabetical presentation of the genetic code found in the table above, find the codon of interest in one of the six right hand columns and locate the corresponding amino acid in the leftmost column. This chart is also useful for finding all codons that correspond to a particular amino acid or Stop.
To interpret a codon using the Genetic Code Large Print Braille, choose the page that has the first letter of the codon in the left column. Then find the second codon letter in the second column of the same page, and then the third codon letter in the third column, which also includes the corresponding amino acid. Note that mRNA codons are always read from the free phosphate side of the first nucleotide to the free sugar side in the third nucleotide. In the example below, the codon is read AUG, which codes for the amino acid Methionine.
How to Demonstrate Translation
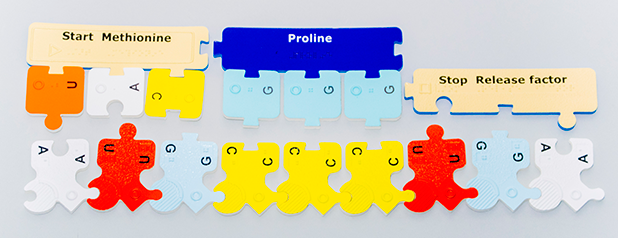
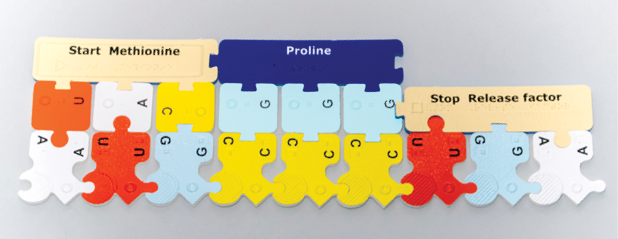
Using the DNA-RNA Kit, construct an mRNA molecule that is at least nine nucleotides long making sure the first three nucleotides are AUG. The AUG triplet codes for the amino acid Methionine which begins the translation process and is represented by the Start Methionine subunit in the PSK. Always construct mRNA strands such that the phosphate side of the first nucleotide and the sugar side of the last nucleotide are free (unlinked). In the photo below, the strand is oriented so that the bases point up. Orientation of the strand can be in any direction, but the nucleotide sequence of mRNA is always read from the free phosphate side of the first nucleotide to the free sugar side of the last nucleotide of the strand (left to right in the photo below).
Using the genetic code, decode the mRNA sequence and determine the amino acids that will make up the protein molecule. In this example AUG, CCC, and UGA code for Start Methionine, Proline, and Stop Release factor, respectively.
Construct the tRNA molecules needed to deliver the appropriate amino acids. The PSK represents tRNA molecules by linking tRNA nucleotide anticodons directly to the appropriate amino acids.
The anticodon part of the tRNA is formed using complementary base-pairing rules for RNA nucleotides. For example, the anticodon of AUG is UAC; attach these tRNA nucleotides to the Start Methionine subunit. Likewise, attach GGG tRNA nucleotides to the amino acid Proline. Then choose the Release factor that fits the Stop codon in the mRNA sequence.
Note: When the Start or amino acid subunits are oriented with tabs pointed down, the tRNA anticodon nucleotides are attached and read from left to right. Orientation of tRNA anticodons can be in any direction but the nucleotide sequence of the anticodon triplet is always read from the sugar side (raised circle tactile symbol) to the phosphate (flat) side of each tRNA nucleotide subunit.
Attach the prepared tRNA molecules to the appropriate places on the mRNA molecule and link the amino acids together horizontally. The linkages between amino acids represent peptide bonds between the carboxyl end (C-terminus) of the first amino acid and the amino end (N-terminus) of the next amino acid.
Remove the mRNA and tRNA nucleotides as well as the Release factor to reveal the primary structure of a protein: a specific sequence of amino acids.
From DNA to Protein
The steps of this process through transcription are demonstrated using the DNA and RNA nucleotide subunits from the DNA-RNA Kit.
This figure shows a length of double-stranded DNA with the gene of interest (lower strand). Note how the two attached DNA strands are antiparallel—that is, the upper strand has a free sugar on the left and a free phosphate on the right, and the lower strand has a free phosphate on the left and a free sugar on the right. This demonstrates how both the nucleotides and the strands have directionality.
This figure shows the same DNA separated into two single strands.
This figure shows just the DNA template strand.
Transcription
The DNA template strand is used to form a strand of mRNA. Begin base-pairing mRNA nucleotide subunits at the free sugar side of the DNA template strand: RNA adenine (A) attaches to DNA thymine (T). Make sure the RNA strand has a free phosphate side at its starting point.
Continue attaching RNA subunits, always adding new nucleotides to the sugar side of the growing mRNA strand.
Continue attaching RNA subunits using DNA to RNA base-pairing rules until the whole DNA template strand is transcribed. Note how the DNA template strand and the mRNA strand are antiparallel—that is, the upper mRNA strand has a free sugar on the left and a free phosphate on the right, and the lower strand (DNA template) has a free phosphate on the left and a free sugar on the right (just as in double-stranded DNA.)
Separate the mRNA from the DNA template strand; the mRNA is now complete.
Translation
This is the process of translating a sequence of nucleotides from the mRNA to a sequence of amino acids, thus forming the primary structure of a protein. Reorient the mRNA strand so the bases point up and the strand can be read from free phosphate side to free sugar side (left to right).
Decode each triplet and prepare tRNA anticodon and amino acid combinations using tRNA nucleotide subunits and amino acid subunits from the PSK.
Line up and attach tRNA anticodons and the Stop Release factor to mRNA codons, and amino acids to each other.
Detach the tRNA anticodons from the amino acids and remove the Stop Release factor to reveal the correct amino acid sequence or polypeptide. This represents the primary structure of a protein.
Alignment with Disciplinary Core Ideas – Life Sciences and Next Generation Science Standards1
Disciplinary Core Ideas
LS1.A: Structure and Function
All cells contain genetic information in the form of DNA molecules. Genes are regions in the DNA that contain the instructions that code for the formation of proteins, which carry out most of the work of cells. (HS-LS1-1)
LS3.A: Inheritance of Traits
Each chromosome consists of a single very long DNA molecule, and each gene on a chromosome is a particular segment of that DNA. The instructions for forming species’ characteristics are carried in DNA. All cells in an organism have the same genetic content, but the genes used (expressed) by the cell may be regulated in different ways. Not all DNA codes for a protein; some segments of DNA are involved in regulatory or structural functions, and some have no known function. (HS-LS3-1)
1 NGSS Lead States. 2013. Next Generation Science Standards: For States, By States. Washington, DC: The National Academies Press.